Meta 推出 ARE 和 Gaia2,提升智能体真实场景适应力
快速阅读: Meta推出新评估平台ARE及基准模型Gaia2,模拟现实世界环境,评估智能体在动态条件下的适应能力。Gaia2支持多协议,测试智能体应对变化条件、故障及模糊指令的表现,OpenAI的GPT-5在测试中领先。
在智能体性能评估领域,如何有效测试其在真实场景中的表现一直是个亟待解决的问题。尽管市场上已有多个评估基准尝试解决此问题,但 Meta 的研究人员认为,现有方法仍不足以真实反映智能体的适应能力。为此,Meta 推出了新的评估平台——Agents Research Environment (ARE) 和全新的基准模型 Gaia2,旨在帮助评估智能体在实际应用中的表现。
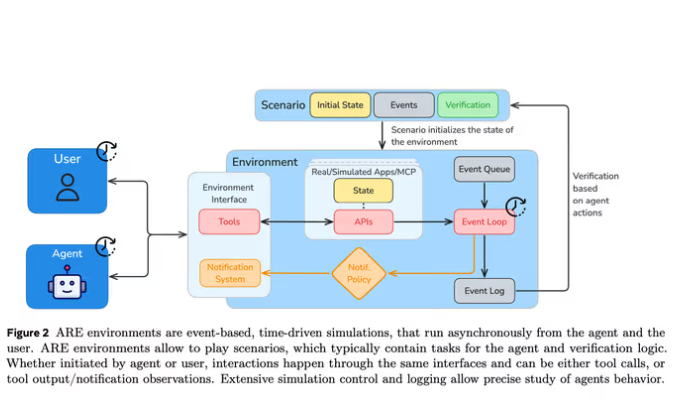
ARE 的设计目标是创建一个类似现实世界的环境,让智能体在其中进行交互。该环境中的任务异步进行,时间持续流动,智能体需在动态条件下调整和执行任务。ARE 的关键元素包括状态保持的 API 接口、环境集合、事件、通知和场景等,用户可根据自身需求自定义测试场景。
作为 ARE 的核心部分,Gaia2 专注于评估智能体在复杂环境中的能力。与早期的 Gaia1 基准不同,Gaia2 不仅考察智能体寻找答案的能力,还评估它们应对不断变化的条件、截止日期、API 故障及模糊指令的表现。此外,Gaia2 支持多种协议,如 Agent2Agent,用于评估智能体间的协作能力。
Gaia2 的评估过程异步进行,即便智能体处于空闲状态,时间依旧流逝,这有助于衡量智能体在接收到新事件时的响应能力。通过在动态环境中进行的1120项任务测试,结果显示 OpenAI 的 GPT-5 在 Gaia2 基准上表现突出,居于领先地位。
除 Meta 的 Gaia2 外,市场上还有其他提供真实环境测试的评估平台,例如 Hugging Face 的 Yourbench、Salesforce 的 MCPEval 和 Inclusion AI 的 Inclusion Arena。这些平台各有侧重点,而 Gaia2 特别强调智能体的适应能力和处理突发事件的能力,为企业提供了一种有效的智能体性能评估方式。
(以上内容均由Ai生成)