英伟达开源Audio2Face,实时生成虚拟角色面部动画
快速阅读: 英伟达开源Audio2Face模型,提升虚拟角色面部动画生成技术。支持离线渲染和实时流式处理,已广泛应用于游戏开发,简化制作流程并提升角色真实感。
近日,英伟达宣布开源其生成式AI面部动画模型Audio2Face。该模型不仅包含核心算法,还提供软件开发工具包(SDK)及完整的训练框架,旨在加速游戏和3D应用中智能虚拟角色的开发。
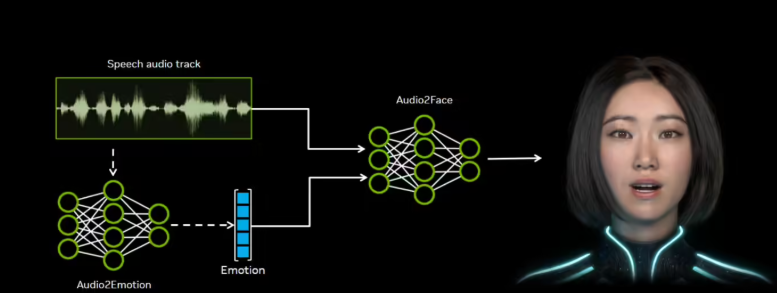
Audio2Face通过分析音频中的音素、语调等声学特征,能实时驱动虚拟角色的面部动作,生成精确的口型同步和自然的情感表情。这项技术适用于游戏、影视制作和客户服务等多个领域。
Audio2Face模型支持两种运行模式:一种是针对预录制音频的离线渲染,另一种是支持动态AI角色的实时流式处理。为方便开发者使用,英伟达还开源了多个关键组件,包括Audio2Face SDK、适用于Autodesk Maya的本地执行插件,以及针对Unreal Engine 5.5及以上版本的插件。此外,回归模型和扩散模型也一并开源,开发者可利用开源训练框架,使用自己的数据对模型进行微调,以适应特定应用场景。
目前,这项技术已被多家游戏开发商广泛应用。游戏开发公司Survios在其游戏《异形:侠盗入侵进化版》中集成了Audio2Face,显著简化了口型同步与面部捕捉的流程。Farm51工作室在《切尔诺贝利人2:禁区》中也应用了该技术,通过音频直接生成细腻的面部动画,节省了大量制作时间,提升了角色的真实感和沉浸体验。该工作室的创新总监Wojciech Pazdur对此表示,这一技术堪称“革命性突破”。
英伟达的这一新举措无疑为开发者提供了更多创作工具,也将推动虚拟角色表现的进一步发展。随着技术的进步,未来我们有望在游戏和影视作品中看到更加真实和生动的角色表现。
入口:https://build.nvidia.com/nvidia/audio2face-3d
划重点:
– 英伟达开源Audio2Face模型,旨在提升虚拟角色的面部动画生成技术。
– 支持离线渲染和实时流式处理,适用于多种场景。
– 已被多个游戏开发商采用,简化了制作流程并提升了角色的真实感。
(以上内容均由Ai生成)







