阿里云发布全球首个全模态AI模型Qwen3-Omni,支持多语言处理
快速阅读: 阿里云发布Qwen3-Omni,全球首个原生端到端全模态AI模型,支持119种文本语言和19种语音输入,处理文本、图像、音频和视频,性能领先。
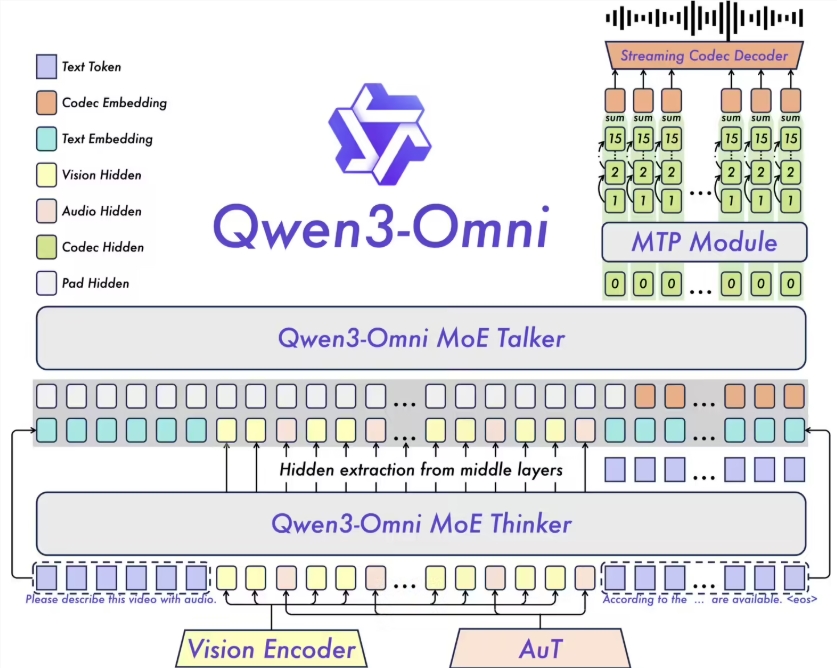
阿里云发布了Qwen3-Omni,标志着全球首个原生端到端全模态AI模型的诞生,该模型现已开源。Qwen3-Omni能够处理文本、图像、音频和视频等多种输入类型,实现快速响应,无论是通过文本还是自然语音,均能实现实时流式输出。
Qwen3-Omni在多个领域展现了跨模态的卓越表现。经过早期以文本为中心的预训练和混合多模态训练,该模型具备强大的多模态处理能力,在音频和视频性能上尤为突出,同时在文本和图像处理上也达到高标准。根据36项音频和视频基准测试,Qwen3-Omni在22项测试中达到最新领先水平,特别是在自动语音识别和音频理解等领域,其表现与行业内的Gemini2.5Pro相当。
Qwen3-Omni支持119种文本语言和19种语音输入语言,以及10种语音输出语言,包括英语、中文、法语和德语等,使其能够更好地服务于全球用户。该模型采用MoE(专家混合)系统和AuT预训练技术,确保了强大的通用表征能力。多码本设计保证了低延迟的实时音频和视频交互,支持自然对话的流畅进行。
除了Qwen3-Omni,阿里云还推出了Qwen3-TTS,这是一款支持17种音色选择的文本转语音模型。该模型在多项评估基准中表现出色,尤其是在语音稳定性和音色相似度方面超越了多款竞品。
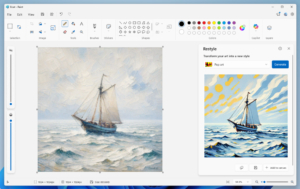
Qwen-Image-Edit-2509是另一款新推出的工具,专注于多图像支持的图像编辑,显著提高了编辑的一致性和效果。它不仅能处理单张图像,还支持多图像的拼接编辑,满足更复杂的编辑需求。
GitHub: https://github.com/QwenLM/Qwen3-Omni
huggingface: https://huggingface.co/collections/Qwen/qwen3-omni-68d100a86cd0906843ceccbe
重点:
🌟 Qwen3-Omni是全球首个原生端到端全模态AI模型,支持文本、图像、音频和视频的统一处理。
🌐 模型支持119种文本语言和19种语音输入,能够满足全球用户的多语言需求。
🖼️ 新发布的Qwen-Image-Edit-2509支持多图像编辑,显著提升编辑的一致性和效果。
(以上内容均由Ai生成)