机器人学会用强化学习塑造沙子
快速阅读: 波恩大学研发的强化学习框架使机器人能精准塑造沙子等颗粒材料,达到毫米级精度。该系统在多种基准测试中表现优异,无需额外训练即可从模拟环境迁移到实际应用。
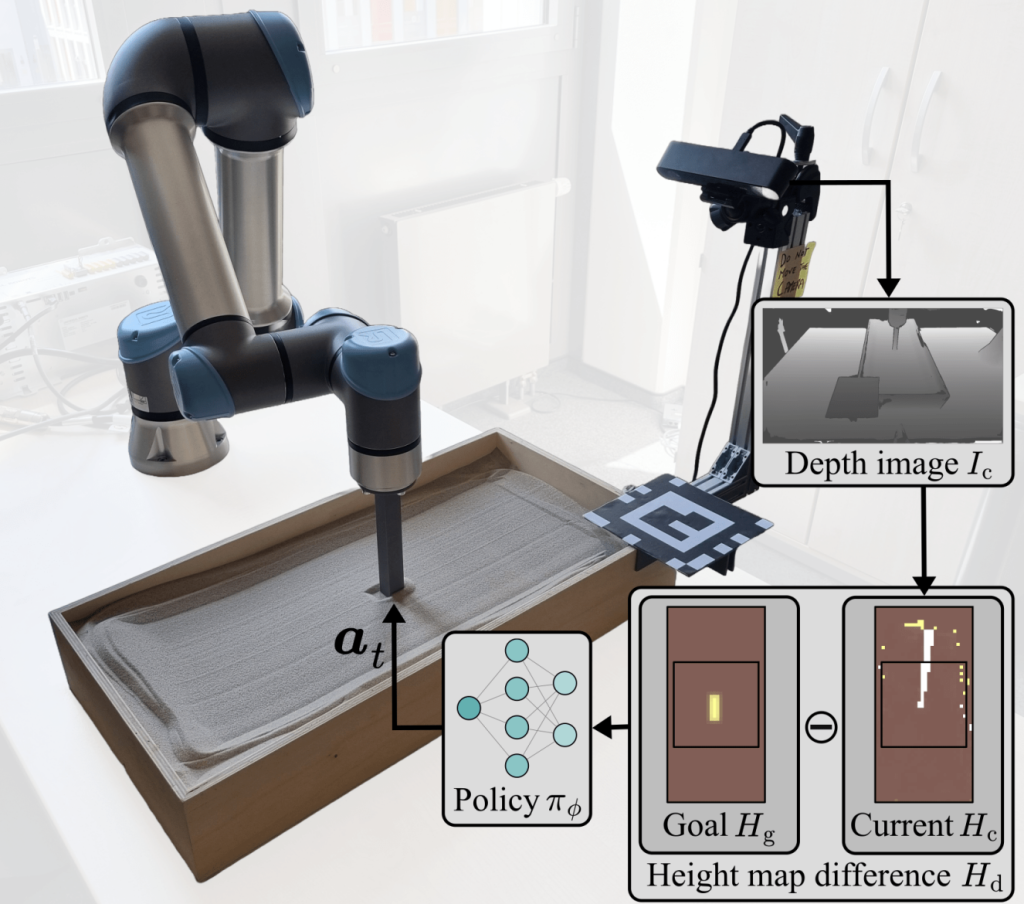
一项发表在arXiv上的研究详细介绍了波恩大学研究人员开发的一种强化学习框架,该框架使机器人能够将沙子等颗粒材料塑造成目标形状。该系统训练了一个带有立方体末端执行器和立体相机的机械臂,可以将松散材料重塑成矩形、L形、多边形以及考古壁画碎片的负模等形状。实验显示,该系统达到了毫米级精度,训练出的代理在两种基准方法中表现最佳,并且无需额外训练即可从模拟环境成功转移到实际机器人上。
颗粒材料因其高维度配置空间和不稳定的动力学特性,给机器人操作带来了挑战。基于规则的方法通常失败,而粒子模拟计算成本高昂。研究人员通过设计紧凑的观察空间和奖励函数来解决这些难题,从而指导学习过程。视觉策略使用截断量化批评者(TQC)算法进行训练,这是一种离策略强化学习算法。来自ZED 2i立体相机的深度图像被转换成高度图,使机器人能够在适合高效训练的形式下比较当前结构和目标结构。
机器人的任务是使用其立方体末端执行器操纵颗粒材料,使其尽可能接近所需的目标配置。该系统在随机策略和Boustrophedon覆盖路径规划基线上进行了评估。在400个目标形状中,学习到的代理始终优于这两种方法。使用delta奖励(DELTA)公式,机器人实现了平均3.4毫米的高度差,而规划方法为4.8毫米,随机运动为7.2毫米。执行时间也较短,平均23.5步,而路径规划基线为44步。代理还修改了目标区域中97%的相关单元,而随机运动仅为54%。执行步骤定义为末端执行器离开颗粒介质连续三步的动作数。统计测试证实,DELTA策略显著优于所有其他方法。
该项目涉及波恩大学的人形机器人实验室、自主智能系统实验室和机器人中心,以及拉马尔机器学习与人工智能研究所的合作。资金来自欧洲委员会的RePAIR项目,属于地平线2020计划,以及德国联邦教育和研究部通过德国机器人研究所倡议提供的支持。
进一步的实验探讨了设计选择。当移除目标区域移动奖励时,代理完全避免了操纵行为,表现不比随机基线好。特征提取器的消融研究表明,所提出的门控编码器表现最佳,平均误差为3.4毫米,而直接依赖深度图像时为4.6毫米。算法比较确认TQC实现了稳定收敛,而软演员评论家算法滞后,双延迟深度确定性策略梯度未能收敛。论文链接的补充网站提供了更多细节、视频和代码。
在UR5e机械臂上的部署验证了该方法在模拟之外的实际应用。尽管存在传感器噪声和不平整的起始表面,机器人仍能重现类似模拟中的矩形等目标形状。这种直接从合成训练环境转移到现实世界执行的能力展示了该框架的稳健性。
关于颗粒材料的操作研究涵盖了挖掘、分级和外星土壤处理等领域。许多方法依赖于计算密集型的有限元或离散元模拟,或是针对特定任务的模仿学习管道。通过结合高效的高程图表示和精心设计的奖励公式,波恩团队证明,强化学习可以在没有手工规则的情况下自适应地塑造颗粒材料。作者总结说,他们的方法始终优于传统基线,并为可变形材料的自适应机器人操作提供了一条可行的途径。
有关能源和增材制造未来对话的AMA: Energy 2025会议名额有限,请立即注册参加。准备好发现谁赢得了2024年3D打印行业奖了吗?订阅3D打印行业通讯,并关注我们的LinkedIn,以获取最新新闻和见解。
图片显示,通过感官输入训练代理以操作颗粒介质的过程。图片来源:波恩大学。
(以上内容均由Ai生成)







