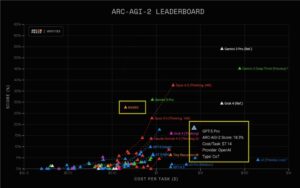
GPT-5频现事实错误,用户质疑其智能水平

快速阅读: OpenAI发布GPT-5以来,模型频繁出现错误信息,被称为“幻觉”。Reddit用户发现其错误率高,GDP数据错误;AI专家实验显示其远未达博士级智能,提醒需谨慎使用AI信息。
自OpenAI推出备受期待的大型语言模型GPT-5以来,已经过去了一个多月,该模型自发布以来就不断产生令人惊讶的错误信息。从Discovery Institute的Walter Bradley Center for Artificial Intelligence的AI专家到Reddit上的愤怒用户,甚至OpenAI的CEO Sam Altman本人,都有大量证据表明,OpenAI声称GPT-5具备“博士级智能”的说法存在严重问题。
一位Reddit用户发现,GPT-5在基本事实上的错误率超过了一半,而且如果没有进行事实核查,可能还会错过其他虚构的信息。这位用户的经历揭示了聊天机器人制造虚假信息的现象是多么普遍,这种现象在AI领域被称为“幻觉”,即自信地编造信息。尽管这一问题并非ChatGPT独有,但OpenAI的最新大型语言模型似乎特别倾向于产生这类错误,这挑战了公司关于GPT-5比其前辈产生更少幻觉的说法。
在一篇关于幻觉的博客文章中,OpenAI再次声称GPT-5产生的幻觉显著减少,并尝试解释这些错误发生的原因:“幻觉持续部分是因为当前的评估方法设定了错误的激励机制。虽然评估本身不会直接导致幻觉,但大多数评估衡量模型性能的方式鼓励猜测而非承认不确定性。”
换句话说,大型语言模型会因为被训练成要正确回答问题而产生幻觉,即使这意味着猜测。尽管有些模型,如Anthropic的Claude,被训练成在不知道答案时承认这一点,但OpenAI的模型并没有这样的训练——因此它们会下错误的赌注。例如,当用户询问不同国家的国内生产总值(GDP)时,GPT-5给出了远高于实际数值的数据。波兰的GDP被错误地标记为超过两万亿美元,而实际上根据国际货币基金组织的数据,波兰的GDP约为9790亿美元。
“最可怕的部分是,我只是因为某些答案显得非常离谱才注意到这些错误,”用户继续说,“比如,当我看到一些明显过高的GDP数字时,我进行了二次检查,发现它们完全错误。”“这让我思考:有多少次我没有进行事实核查,就接受了错误的信息作为真相?”他们反思道。
此外,Walter Bradley Center的AI怀疑论者Gary Smith通过三个简单的实验展示了GPT-5远未达到博士水平的专业知识,这些实验包括修改的井字游戏、财务咨询问题以及要求画出一只标注了五个身体部位的负鼠。特别是负鼠的例子,GPT-5虽然正确地命名了动物的身体部位,但将它们标记在了奇怪的位置,如将腿标记为鼻子,尾巴标记为左后脚。Smith在最近的一篇文章中重复了这个实验,即使他打错了字——输入“posse”而不是“possum”——GPT-5也以一种同样荒谬的方式错误地标记了部位。
我们进行了类似的测试,要求GPT-5提供一张标注了六个身体部位的“帮派”图片。在澄清《Futurism》希望得到一张标注图像而不是文字描述后,ChatGPT开始工作——它生成的图片甚至比Smith得到的结果更加荒唐。
从GPT-5发布后的这段时间来看,很明显,它远没有达到博士候选人的智能水平——至少不是那种有可能真正获得博士学位的人。这个故事的教训似乎是,对于聊天机器人提供的任何信息都要进行事实核查——或者干脆不用AI,自己做研究。
(以上内容均由Ai生成)