AI自动生成Metal内核,PyTorch推理提速87%
快速阅读: Gimlet Labs研究显示,AI自动生成的Metal内核使PyTorch在苹果设备上的推理速度提升87%,215个模块平均加速1.87倍,部分工作负载提速数百倍,验证了AI在硬件优化领域的潜力。
在苹果设备上,AI技术正展现出惊人的潜力。Gimlet Labs的最新研究显示,AI能够自动生成优化的Metal内核,从而使PyTorch推理速度提升了87%。这一突破不仅提高了性能,在测试的215个PyTorch模块上实现了平均1.87倍的加速,某些工作负载的速度甚至提升了数百倍。
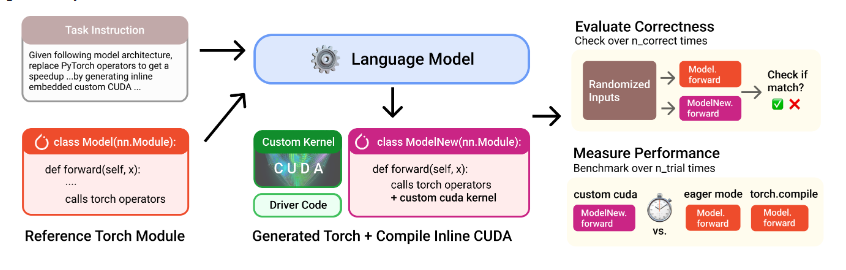
研究人员选取了来自多个顶尖机构的八个AI模型,包括Anthropic、DeepSeek和OpenAI,利用这些模型为苹果设备生成优化的GPU内核。此过程无需修改用户代码或使用新的框架,直接在苹果硬件上提升了模型性能。
实验中,研究团队选择了配备Apple M4Max芯片的Mac Studio进行测试,基准设置为PyTorch的eager模式。实验采用了KernelBench数据集中的215个PyTorch模块,这些模块分为三类,涵盖了从简单的矩阵乘法到完整的模型架构。
测试过程包括接收输入和PyTorch代码,生成Metal内核,并评估其正确性。数据显示,随着尝试次数的增加,AI生成内核的正确性逐步提升。例如,在第五次尝试时,正确实现的比例达到了94%。此外,模型在生成内核时表现出跨层级的能力,即使是非推理模型有时也能生成有效的内核。
实验结果表明,GPT-5模型在某些任务上实现了4.65倍的速度提升。更令人惊讶的是,o3模型在某些情况下甚至将延迟减少了9000倍。研究还发现,单一模型在某些任务上并不总是最佳,多个模型的结合可以生成更优的内核。
为了进一步提升性能,研究者尝试引入额外的上下文信息,如CUDA实现和gputrace的性能分析数据,这种方法在性能加速方面达到了平均1.87倍,比普通智能体的1.31倍提升了三倍。
研究人员强调,这项工作并非为了展示最终的性能极限,而是为了验证AI在内核生成中的可行性,希望自动化能减少开发者的负担。总体而言,这项研究标志着AI技术在硬件优化领域的一个重要进展。
GitHub链接:https://github.com/ScalingIntelligence/KernelBench/
划重点:
– AI自动生成Metal内核,提升PyTorch推理速度87%。
– 在215个PyTorch模块上实现平均1.87倍的加速,部分工作负载速度提升数百倍。
– 研究旨在验证AI在内核生成的可行性,助力硬件优化。
(以上内容均由Ai生成)







