清华东北大学联手发布UltraRAG2.0,50行代码实现高性能RAG系统
快速阅读: 清华大学与东北大学联合发布UltraRAG2.0,简化RAG系统构建,用户通过YAML文件实现复杂逻辑,代码量减少至50行,性能提升12%。
近日,清华大学THUNLP实验室、东北大学NEUIR实验室与OpenBMB及AI9Stars联合发布了UltraRAG2.0。这是首个基于Model Context Protocol (MCP)架构设计的检索增强生成(RAG)框架。该框架旨在简化RAG系统的构建,使科研人员能在短时间内实现复杂的多阶段推理系统。UltraRAG2.0的主要优势在于用户只需编写YAML文件,即可轻松声明复杂的逻辑操作,如串行、循环和条件分支,从而显著减少代码量,降低实现难度。
当前,RAG的发展趋势中,许多系统开始融合自适应知识组织、多轮推理及动态检索等复杂特性,代表项目有DeepResearch和Search-o1。然而,这些高级特性也增加了开发者的工程成本,限制了新想法的快速迭代与复现。UltraRAG2.0的推出正是为了应对这一挑战,它通过将RAG的核心组件封装为独立的MCP服务器,实现了功能的灵活调用和扩展。
与传统实现方式相比,UltraRAG2.0大幅减少了代码量。例如,经典方法IRCoT的官方实现需要近900行代码,而使用UltraRAG2.0只需约50行代码即可完成相同的功能。其中,一半的代码用于流程编排的YAML伪代码,极大地降低了开发门槛。该框架支持通过简洁的声明式方式构建多阶段推理流程,使得复杂的推理逻辑无需冗长的手动编码。
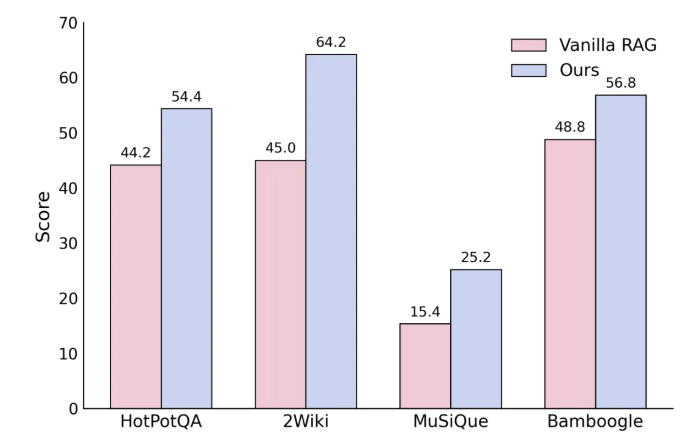
此外,UltraRAG2.0还支持动态检索、条件判断及多轮交互等高级功能,科研人员可以迅速搭建高性能的实验平台,满足复杂多跳问题的需求。其性能比传统的Vanilla RAG提高了约12%。该系统的设计目标是帮助研究者节省工程实现的时间和精力,让他们能够更多地关注算法创新和实验设计。
UltraRAG2.0的MCP架构还允许不同模块间的无缝复用,并支持模块的灵活扩展和接入,便于科研人员快速适配新的模型和算法,进一步提升了系统开发的效率和可复现性。
GitHub: https://github.com/OpenBMB/UltraRAG
项目主页: https://openbmb.github.io/UltraRAG
划重点:
🌟 UltraRAG2.0由清华大学与东北大学联合推出,旨在简化复杂的RAG系统构建。
🛠️ 用户通过编写YAML文件即可实现复杂推理逻辑,大幅降低代码量与开发门槛。
📈 相较于传统方法,UltraRAG2.0在性能上提升约12%,适用于多轮推理和动态检索等高级功能。
(以上内容均由Ai生成)







