腾讯R-Zero展示大模型自我训练能力,告别数据标注
快速阅读: 腾讯AI实验室与圣路易斯华盛顿大学开发R-Zero框架,使大型语言模型无需人类标注数据即可自我改进,显著提升推理能力,降低成本,加速复杂任务模型开发。
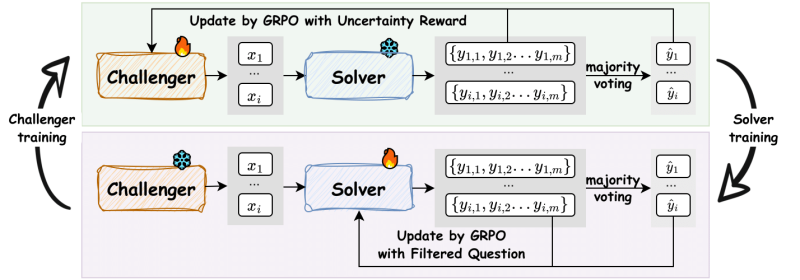
腾讯AI实验室与圣路易斯华盛顿大学的研究人员开发了一种新的训练框架,使大型语言模型(LLM)能够在无需人类标注数据的情况下自我改进。这种名为R-Zero的技术利用强化学习自动生成训练数据,解决了创建自进化AI系统的主要瓶颈之一。R-Zero通过两个独立模型相互作用和挑战对方来实现共同进化。
实验表明,R-Zero显著提升了不同LLM的推理能力,这可能降低高级AI训练的复杂性和成本。对企业而言,这种方法可以加速专门用于复杂推理任务的模型开发,而无需耗费大量资源来整理标注数据集。
Visa投资35亿美元押注AI领域
自进化LLM的核心理念是创建能够自主生成、精炼并从自身经验中学习的AI系统。这为更智能和强大的AI提供了一条可扩展的路径。然而,训练这些模型需要大量的高质量任务和标签,作为AI学习的监督信号。依赖人工标注数据不仅成本高昂且速度慢,还成为AI潜力发展的根本瓶颈。为解决这一问题,研究人员开发了无需标签的方法,直接从模型的输出中提取奖励信号,例如通过测量其对答案的信心。虽然这些方法消除了对显式标签的需求,但仍依赖于预设的任务集,限制了其在真正自进化场景中的应用。
AI扩展面临极限
功耗上限、不断上涨的令牌成本和推理延迟正在重塑企业AI。顶尖团队正采取行动:
– 将能源转化为战略优势
– 构建高效的推理架构以实现真正的吞吐量提升
– 通过可持续的AI系统解锁竞争优势回报
其他方法涉及让模型生成自己的学习任务。但在开放性推理等领域,由于没有简单的方法来验证正确性(如代码执行器),确保自生成数据的质量成为重大障碍。
R-Zero的工作原理
R-Zero是一个旨在训练从零外部数据开始进化的推理LLM的框架。过程从一个基础模型开始,该模型分为“挑战者”和“解题者”两个角色。这两个模型独立优化,但通过持续的互动周期共同进化。
挑战者的任务是创建刚好处于解题者当前能力边缘的新任务,既不太容易也不太难。解题者则因解决这些日益复杂的任务而获得奖励。论文合著者、圣路易斯华盛顿大学博士生黄成松在接受VentureBeat采访时指出,这种动态关系至关重要,因为生成高质量问题是比找到答案更复杂的任务。
“我们在实际操作中发现,最大的挑战不是生成答案……而是生成高质量、新颖且逐渐增加难度的问题。”黄成松说,“我们认为,好老师远比好学生稀有。共同进化动态自动化地创造了这个‘老师’,确保了一个稳定且动态的课程,推动解题者的能力远远超过静态预设数据集所能达到的水平。”
当挑战者生成足够多的问题后,这些问题经过筛选以确保多样性,并编入训练数据集。在解题者的训练阶段,它会在这些具有挑战性的问题上进行微调。每个问题的“正确”答案由解题者之前的尝试多数投票决定。
整个过程不断重复,形成一个无需人为干预的自我改进循环,使两个模型在每次迭代中都变得更加优秀。
R-Zero的实际应用
研究人员在多个开源LLM上测试了R-Zero,包括来自Qwen3和OctoThinker系列的模型。他们首先在数学问题上训练这些模型,然后测试所学推理技能是否能推广到其他复杂的一般领域基准测试,如MMLU-Pro(多语言理解和推理任务)和SuperGPQA(科学和推理任务)。
研究结果显示,R-Zero 是一个高效且适用于多种模型的框架。例如,在数学推理基准测试中,R-Zero 将 Qwen3-4B-Base 模型的平均得分提高了 6.49 分。训练过程显著提升了性能,多次迭代后效果更加明显。Qwen3-8B-Base 模型经过三次迭代后,其平均数学得分提高了 5.51 分。
研究人员发现,第一次迭代后性能立即提升,这验证了挑战者在创建高质量学习课程中的有效性。“这表明,由强化学习训练的挑战者生成的智能课程比未训练的生成器更有效。” 研究人员在论文中写道。
值得注意的是,从数学问题中学到的技能可以有效转移到一般推理任务中,从而增强模型的基本能力。例如,同一 Qwen3-4B-Base 模型在一般领域推理基准测试中的表现提高了 7.54 分。另一个重要发现是,R-Zero 可以作为预训练的关键步骤。首先通过 R-Zero 提升的模型,在后续使用传统标注数据微调时,表现更加出色,表明该框架具有放大性能的效果。
对于企业而言,“零数据”方法可能是一个重大突破,特别是在高质量数据稀缺或不存在的利基领域。黄指出,R-Zero 的主要优势在于能够绕过人工智能开发中最昂贵和耗时的部分——数据管理。“我们的方法完全绕过了寻找、标注和管理高质量数据这一基本瓶颈。” 他说,“这不仅是一种成本节约措施,还是一条通向超越人类能力的 AI 发展路径,因为 AI 不再受制于人类知识或数据的范围。”
然而,共进化过程也揭示了一个关键挑战。随着挑战者成功生成越来越难的问题,求解者的多数投票产生可靠“正确”答案的能力开始下降。研究人员发现,这些自动生成标签的真实准确性从第一次迭代的 79% 下降到第三次迭代的 63%,与强大的 GPT-4 相比,数据质量的下降成为系统长期性能的一个关键权衡和潜在瓶颈。
黄承认,这是一个自我进化范式的基本问题。“我们的工作证明了这种方法的潜力,但我们承认,保持稳定、长期改进而不停滞是一个重大障碍。” 他说,“解决这个问题将是整个研究社区面临的下一个关键步骤。”
研究人员还指出了框架的一个局限性:当前机制最适合像数学这样可以客观确定正确性的领域。那么,如何将这一强大范式扩展到更主观的企业任务,如生成营销文案或总结报告呢?
黄建议,一个可能的解决方案是引入第三个共进化的 AI 代理——“验证者”或“评论者”。“这个验证者将接受训练,评估求解者输出的质量,而不仅仅是简单的‘正确’答案。” 他解释道,“共进化动态将涉及挑战者创建提示,求解者生成响应,验证者提供质量信号,三个模型共同进步。”
尽管这仍然是未来研究的方向,但它指向了一个未来,即完全自主的 AI 系统不仅能掌握客观逻辑,还能处理主观推理。
(以上内容均由Ai生成)







