谷歌发布香蕉模型,超越GPT-4和FLUX,称霸AI图像领域
快速阅读: 谷歌推出Gemini 2.5 Flash Image,具备强大图像编辑能力,支持多图融合与自然语言修改,广泛应用于广告、视频创作等领域,排名全球第一,已在AI Studio上线。
谷歌于8月27日推出Gemini 2.5 Flash Image,这是该公司最先进的图像生成和编辑模型。该模型的主要亮点在于强大的图像编辑能力,能够将多个图像混合成单一图像,同时保持高度的角色一致性。此外,它支持通过自然语言进行有针对性的修改,并能利用Gemini的世界知识。
这些功能带来了许多有趣的应用场景,例如根据特定视觉模板创建类似“球星卡”的设计,使普通用户也能体验到顶级运动员的待遇。该模型与谷歌的Veo 3等视频生成模型配合使用,可以创造出丰富多彩的视频效果。海外AI创意平台Kera AI已经利用类似模式制作了一部广告大片。
诺贝尔奖得主、谷歌DeepMind联合创始人兼CEO Demis Hassabis专门在推特上用个人照片宣传新模型,展示了Gemini 2.5 Flash Image的角色一致性。他将照片背景改为古典风格,但人物面部特征保持不变。
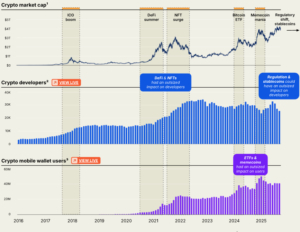
这款模型上周以“nano-banana(小香蕉)”的代号出现在大模型竞技场中,获得了超过200万票的支持。正式发布后,Gemini 2.5 Flash Image在文本生成图像和图像编辑两个领域均排名全球第一,在图像编辑榜单上得分1362,比第二名高出近15%。
根据谷歌公布的基准测试,Gemini 2.5 Flash Image在用户综合喜好度、人物、创造力、信息图、物体和环境的生成方面均优于GPT-4图像生成、Flux.1 Kontext(max)、Qwen Image Edit等模型,但在风格化能力上仍与GPT-4图像生成存在差距。
Gemini 2.5 Flash Image主要面向开发者,目前可在Gemini API、Google AI Studio及面向企业的Vertex AI中获取。Gemini API地址为https://ai.google.dev/gemini-api/docs/image-generation。该模型的价格为30美元/100万个输出token,每张图像约0.039美元(约合人民币0.28元)。所有其他输入和输出模态均遵循Gemini 2.5 Flash定价。
为了简化使用Gemini 2.5 Flash Image构建AI应用的过程,谷歌对AI Studio的“构建模式”进行了重大更新。开发者可以利用AI快速测试新模型的功能,并在准备发布应用时直接从谷歌AI Studio部署,或将代码保存到GitHub。谷歌还在博客中展示了几个案例,如超强角色一致性,帮助Altman一键穿越。
谷歌的Gemini 2.5 Flash Image允许用户将同一角色置于不同环境中,从多个角度展示单个产品,或生成一致的品牌资产,同时保留主题。用户只需上传一张自拍照,即可生成从50年代到00年代的六张写真,每张都有当时的年代风格,但用户的面貌没有明显变化。智东西上传了一张OpenAI联合创始人兼首席执行官Sam Altman的照片,新模型直接让Altman一键穿越回过去,画面质感超真实,每个年代的服饰、发型都准确还原。
此外,该模型支持使用自然语言进行图像转换和编辑。例如,模型可以模糊图像背景、去除T恤上的污渍、从照片中删除整个人物、改变拍摄对象的姿势、为黑白照片添加颜色等。谷歌在AI Studio中构建了一个照片编辑模板应用,支持对特定区域进行选中和修改,或进行大范围调整和滤镜处理。智东西上传了一张扎克伯格的照片,要求模型微调,让牙齿看起来更白。最终生成的结果显示,修改后扎克伯格的其他外貌特征没有明显变化。
该模型还具备大量世界知识,能够理解手绘插图。谷歌为此打造了一个模板应用,将简单的画布变成互动式教育导师。演示中,Gemini 2.5 Flash Image能够理解手绘的各种画面,并回答用户提出的问题。这种世界知识还使模型能够预测图像的未来变化,具备一定的图像推理能力。例如,当看到气球飞向仙人掌时,模型可以根据用户“预测下一个可能场景”的指令,生成气球破碎的画面。
Gemini 2.5 Flash Image能够理解和合并多个输入图像,这在电子商务等场景中具有很强的实用价值。例如,商家可以在同一场景中用AI生成不同产品的宣传照,或向客户提供家具等产品摆放在真实场景中的样子。谷歌提供了一个案例,只需将左侧的台灯拖拽到右侧的场景中,稍等片刻,就能看到摆放后的效果。模型不仅将台灯元素加入画面,还开启了灯光。多图融合能力还可用于创意图像的生成,例如融合鲸鱼与高山的两张照片,打造出极具视觉冲击力的效果。
Gemini 2.5 Flash Image发布后,海外网友立即开始尝试。一位网友利用该模型为客户打造了月饼广告宣传照,他表示,相同的提示词在Midjourney中需要10倍的调整和微调才能达到类似效果。另一位网友分享了自己利用Gemini 2.5 Flash Image结合Veo 3制作的视频,最终效果十分惊艳。然而,也有用户指出,该模型的审查非常严格,例如无法生成人们手持刀和斧头的画面。
总之,准确的图像编辑能力是图像生成进入实际生产场景的关键。在电商等场景中,这一能力满足了企业用户对精确控制的需求;在娱乐场景中,它为用户提供丰富的体验和玩法。目前,已有国内外多家大模型厂商推出图像编辑模型,这一领域的最新进展值得关注。
(以上内容均由Ai生成)