人工智能研究超出训练范围,引发伦理与安全讨论
快速阅读: 亚利桑那州立大学研究指出,大型语言模型中的“思维链”推理可能是模式匹配而非真实智能,建议开发者谨慎使用并采取严格测试策略。
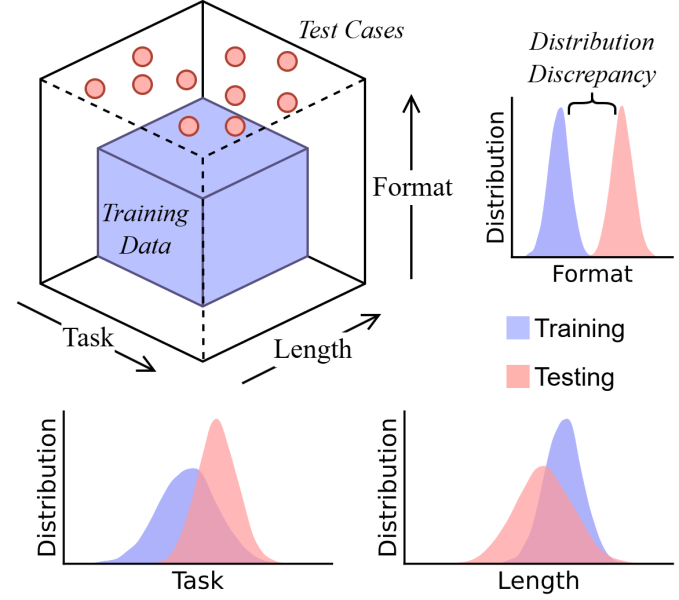
亚利桑那州立大学的研究人员发表了一项新研究,指出大型语言模型(LLM)中备受赞誉的“思维链”(CoT)推理可能只是“脆弱的幻象”,而非真正的智能。这项研究基于越来越多质疑LLM推理深度的工作,但采用独特的“数据分布”视角测试CoT系统性失效的原因。
研究人员不仅批评了现有问题,还提供了实际指导,帮助开发人员在构建LLM驱动的应用时考虑这些限制,包括测试策略和微调的作用。
CoT提示要求LLM“逐步思考”,在复杂任务上表现出色,使人们认为模型能够进行类似人类的推断过程。然而,仔细审查往往揭示出逻辑不一致,挑战了这种观点。多项研究表明,LLM通常依赖表面语义和线索,而非逻辑程序。模型通过重复训练期间见过的模式生成看似合理的逻辑,但在偏离熟悉模板或引入无关信息的任务上经常失败。
尽管有这些观察结果,新研究的作者认为,“系统理解CoT推理为何以及何时失败仍然是一个谜”,他们的研究旨在解决这个问题。此前的研究已经表明,LLM难以推广其推理能力。论文指出,“理论和实验证据显示,当测试输入与训练数据具有潜在结构相似性时,CoT推广良好;否则,性能急剧下降。”
ASU研究人员提出了一种新的视角来看待这个问题:CoT不是推理行为,而是一种复杂的模式匹配,从根本上受制于其训练数据中的统计模式。他们认为,“CoT的成功并非源于模型的内在推理能力,而是其有条件地推广到与训练样本结构相似的分布外(OOD)测试案例的能力。”换句话说,LLM擅长将旧模式应用于看起来相似的新数据,但不擅长解决真正新颖的问题。
为了验证这一假设,他们从三个维度分析了CoT的能力:“任务泛化”测试模型是否能将学到的推理过程应用于新类型的任务;“长度泛化”测试模型是否能处理显著长于或短于训练数据的推理链;“格式泛化”评估模型对提示措辞或结构的微小变化的敏感度。
研究人员开发了一个名为DataAlchemy的框架,在受控环境中从头开始训练较小的LLM,以精确测量超出训练数据时性能的下降情况。
“数据分布视角和受控环境是我们试图传达的核心内容,”ASU博士生、论文合著者郑成帅告诉VentureBeat,“我们希望创造一个空间,让公众、研究人员和开发者自由探索和探究LLM的本质,推动人类知识的边界。”
根据研究结果,研究人员得出结论,CoT推理是“一种复杂的结构化模式匹配,从根本上受制于训练期间看到的数据分布。”当测试稍微超出这个分布时,性能就会崩溃。看似结构化的推理更像是一个幻象,“源自训练数据中的记忆或插值模式,而非逻辑推理。”
研究人员发现,模型在三个维度上表现不佳。面对新任务时,模型无法泛化,而是复制了训练过程中遇到的最接近的模式。在处理不同长度的推理链时,模型也遇到困难,常常试图人为地增加或减少步骤以匹配训练样本的长度。此外,模型的表现对提示中的表面变化非常敏感,特别是核心元素和指令的变化。
有趣的是,研究人员发现这些失败可以迅速解决。通过监督微调(SFT),模型在少量新数据上的性能迅速提升。然而,这种快速修复进一步支持了模式匹配理论,表明模型并未学会更抽象的推理,而是记住了新的模式来克服特定的弱点。
对于企业应用,研究人员直接警告从业者,指出“将链式思维(CoT)作为推理任务的即插即用解决方案存在风险,并且不应将CoT风格的输出等同于人类思考。”他们为开发使用大型语言模型(LLM)的应用程序的开发者提供了三条关键建议:
1. 防止过度依赖和虚假自信。CoT不应被视为高风险领域(如金融或法律分析)中可靠的推理模块。LLM可能产生“流利的胡言乱语”(看似合理但逻辑上有缺陷的推理),比直接错误的答案更具欺骗性。研究者强调,“领域专家的充分审计是不可或缺的。”赵博士表示:“科学的进步应以人类为中心——机器可以辅助,但发现仍然依赖于人类和好奇心。”
2. 重视分布外(OOD)测试。标准验证方法(测试数据与训练数据相似)不足以衡量真正的鲁棒性。开发者必须实施严格的测试,系统地探查任务、长度和格式变化中的失败点。
3. 认识到微调是补丁而非万能药。虽然监督微调(SFT)可以快速“修补”模型在特定新数据分布上的性能,但它不会实现真正的泛化。它只是略微扩大了模型的“分布内”范围。依赖SFT来解决每个OOD失败是不可持续的策略,未能解决模型缺乏抽象推理的核心问题。
尽管CoT不是人类认知的形式,但这一局限性可以管理。大多数企业应用涉及相对狭窄和可预测的任务集。论文的发现为企业确保这些领域的可靠性提供了一个蓝图。开发者可以构建严格的评估套件,系统地测试模型在特定任务、长度和格式变化下的性能。这使他们能够绘制出模型“分布内”舒适区的边界,并确定其与具体需求的契合点。
这种针对性测试将微调从被动的“补丁”转变为积极的对齐策略。当评估揭示出特定弱点时,开发者可以创建小规模、有针对性的SFT数据集来解决这些问题。与其追求广泛的泛化推理,这种方法利用SFT精确地确保模型的模式匹配能力与特定企业任务的需求相匹配。最终,这项研究为超越希望,工程化LLM应用以实现可预测的成功提供了一个实用的视角。
(以上内容均由Ai生成)







