VLM2Vec-V2:统一图像、视频与视觉文档检索
发布时间:2025年7月28日 来源:szf
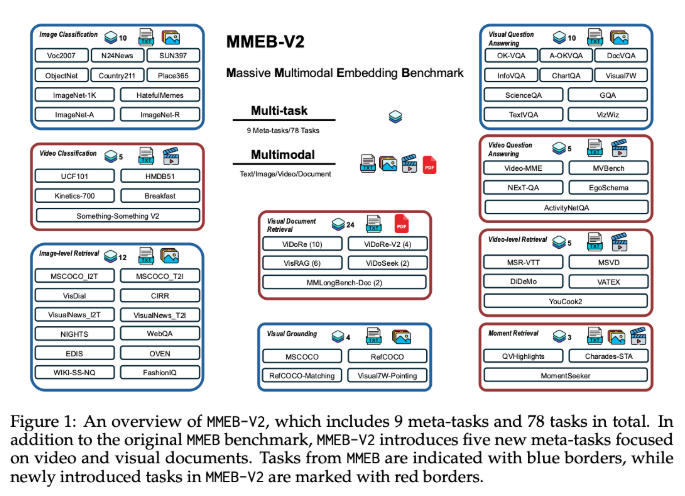
快速阅读: 据相关媒体报道,由Salesforce等联合研发的VLM2Vec-V2框架,提升多模态学习效率与准确性。扩展MMEB数据集,新增五种任务类型,采用Qwen2-VL架构,在78个数据集中取得58.0平均分。
据最新消息,近日,由Salesforce Research、加州大学圣巴巴拉分校、滑铁卢大学及清华大学联合研发的VLM2Vec-V2多模态嵌入学习框架正式发布。该框架旨在统一图像、视频和视觉文档的检索任务,显著提升了多模态学习的效率与准确性。
现有的一些多模态嵌入模型主要基于MSCOCO、Flickr和ImageNet等数据集,集中于自然图像和照片,未能充分覆盖文档、PDF、网站、视频和幻灯片等更广泛的视觉信息类型,限制了它们在实际应用中的表现。针对这一问题,VLM2Vec-V2扩展了MMEB数据集,新增了五种任务类型,包括视觉文档检索、视频检索、时间定位、视频分类和视频问答,为多模态学习提供了更加全面的评估标准。
VLM2Vec-V2采用Qwen2-VL为核心架构,具备简单动态分辨率、多模态旋转位置嵌入(M-RoPE)以及结合二维和三维卷积的统一框架等三大关键特性。通过引入灵活的数据采样管道,该模型能够在多种数据源上进行有效的多任务训练,进一步增强了其在对比学习中的稳定性和泛化能力。
在对78个数据集的综合评估中,VLM2Vec-V2以58.0的平均得分领先多个强基线模型,在图像和视频任务上表现出色。尽管在视觉文档检索方面略逊于ColPali模型,但VLM2Vec-V2仍为多模态学习领域的发展奠定了坚实基础,指明了未来研究的方向。
(以上内容均由AI生成)







