使用非线性终身学习模型预测污水处理厂中的病毒颗粒
快速阅读: 据《Nature.com》称,终身学习框架包括本地机器学习预测与基于知识的适应模块。适应模块通过耦合字典学习调整特征表示,实现知识转移和模型自适应。本地预测器利用稀疏组合优化特征与参数,动态更新字典以提升预测能力。
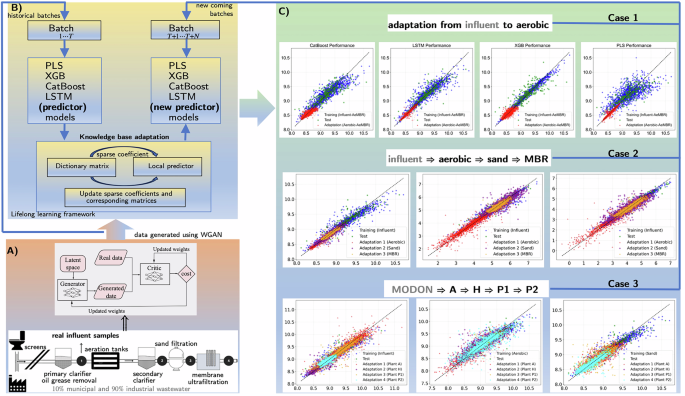
终身学习框架包含两个关键组件:本地机器学习(机器学习)预测模块和基于知识的适应模块。后者结合了耦合字典学习表示(图1),利用WGAN数据生成器(图1A)扩充有限的实际数据,并将其馈送到本地预测器。本地机器学习预测模块基于历史水质输入和病毒颗粒输出批次构建(图1B)。此模块将水质输入编码为特征向量,本地机器学习预测器基于历史输入-输出批次构建预测模型,采用遗传算法和套索方法寻找最佳特征组合。然而,由于其能简化病毒颗粒从进水到不同排放废水基质及污水处理厂的预测过程的优势,保留并选择了包含所有输入特征的最佳特征组合,用于模型适应阶段。当新批次到达且仅提供工艺输入时,触发本地预测器重建的知识转移方案(图25)。
基于知识的适应模块按批次运行,借助耦合字典学习调整输入数据的特征表示,从而间接影响本地预测器的预测能力和学习过程。当新批次到达且仅提供工艺输入时,触发本地预测器重建的知识转移方案(图25)。预测器参数和输入特征向量被分解为共享字典的稀疏组合,以促进知识转移(图1B)。当新批次到达时,本地预测器仅在工艺输入数据上重新训练,并评估损失指数。上述步骤完成后,触发本地预测器重建的知识转移方案。
模型通过不断更新稀疏系数和相应的矩阵进行动态调整,完成自适应调整和字典更新。字典用于表示与各任务相关的特征空间,其矩阵的每一列代表某一任务的特征组合。当其更新时,会改变输入数据在特征空间中的表示方式,从而影响本地预测模型在后续适应过程中解释数据的方式。输入特征向量和预测参数经稀疏矩阵转换,生成稀疏线性组合的新表示。本地预测器模型用于计算稀疏系数向量,该向量表示输入特征或预测参数在稀疏空间中的重要性和权重。
(以上内容均由Ai生成)







