基于内存光学计算的超紧凑型多任务处理器
快速阅读: 据《Nature.com》称,研究提出一种基于光学存内计算的多功能边缘计算系统,通过集成亚波长衍射元件和逻辑神经网络,实现高速低功耗的多样化任务处理,兼具存储与计算功能,展示了光学与电子组件结合在AI应用中的潜力。
在神经网络中,计算通常借助两种组件实现:不同输入数据与相同训练权重的相乘。这一原理同样适用于全连接网络和卷积神经网络。在传统的电子处理器中,此过程需要同时从存储器中访问输入数据和对应的权重。而在这项工作中采用的光学存内计算方法中,经过训练的神经网络权重被集成到芯片上,作为亚波长衍射元件。这意味着网络本身以不同长度的亚波长二氧化硅槽的形式存储,有效将计算参数映射至芯片上的特定物理结构。因此,在计算过程中,只需调制输入数据,无需从存储器中访问网络权重。
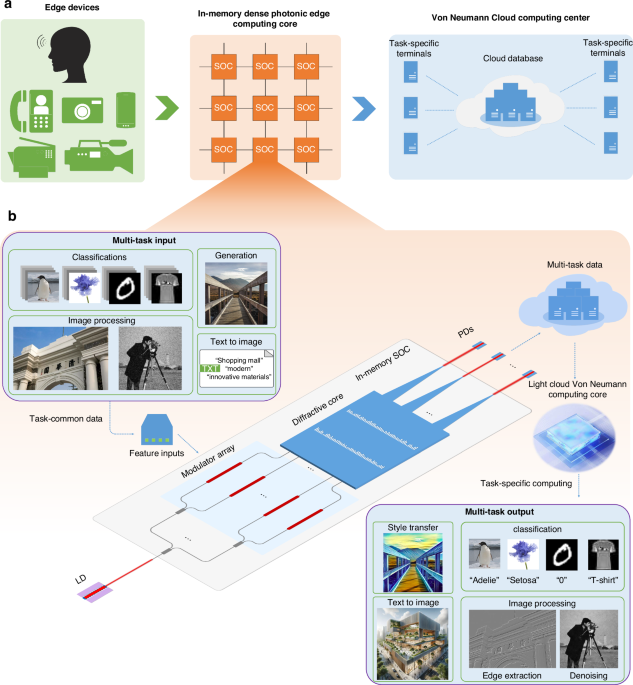
图1a、b所示为所提出的边缘计算多任务系统架构,突出其处理多样化计算任务的能力。这种多功能性是通过系统级芯片(SoC)的创新设计实现的,它并非针对特定任务设计,而是与各种逻辑神经网络(LTNs)结合工作,以解决不同的挑战。如图1a所示,边缘设备获取信息后,通过一系列内部SoC处理多任务输入数据,从而实现高速、低功耗的数据处理。随后,处理后的数据被传输到云端数据库(DB)。根据具体任务需求,不同终端执行多样化的处理任务。具体而言,该过程始于边缘设备获取的输入数据,这些数据经过特征预处理并引入系统数据调制。由调制器阵列完成数据调制,将必要的输入信息编码到入射光上,并经波导导入SoC芯片。
在SoC中,有两个包含亚波长二氧化硅(SiO₂)槽的隐藏层。这些槽具有固定宽度和厚度,长度可变,充当可训练参数。由于这些参数被整合到衍射单元中,单元具备存储和计算能力,从而使SoC过程成为被动的存内计算。通过SoC后,由光电探测器(PD)捕获芯片输出,标志着光学处理阶段的完成。此输出可以传输并存储在云DB中,并与各类终端的LTNs进行接口,实现全面的处理流程。
该系统的灵活性与传统集成型深度光学神经网络(DONN)芯片有显著区别。后者通常设计为执行单一固定任务。相比之下,SoC的功能通过后续的电气处理阶段得到增强,其中特定的LTNs执行最终的任务专用处理。来自不同来源的数据以相位形式编码到光上,并与存内SoC协同处理,参与密集的全光前处理阶段,通过特征识别与提取实现特征的识别和提取。提取的特征通过三条波导传输、归一化并存储以供进一步处理。这些预处理结果最终输入到负责最终任务执行的具体LTNs中,展现系统在处理多样化计算任务中的适应性和高效性。这种方法突显了在人工智能应用中集成光学和电气组件以实现高性能的潜力。
(以上内容均由Ai生成)







